We watched real agents work - actual episodes of agents landing on websites and trying to get things done, drawn from real runs rather than a benchmark built around the formats we ship.
One question: what do they actually reach, in what order, and what do they do with it? The answer is a little uncomfortable for anyone who’s spent the last year shipping llms.txt files.
Agents lean hard on the human web. They reach for homepages and docs - the same pages a person would, in the same order. The purpose-built, agent-first files get used far less. But where those files exist and get reached, they convert better than anything else.
The bottleneck is discovery. Here’s the evidence.
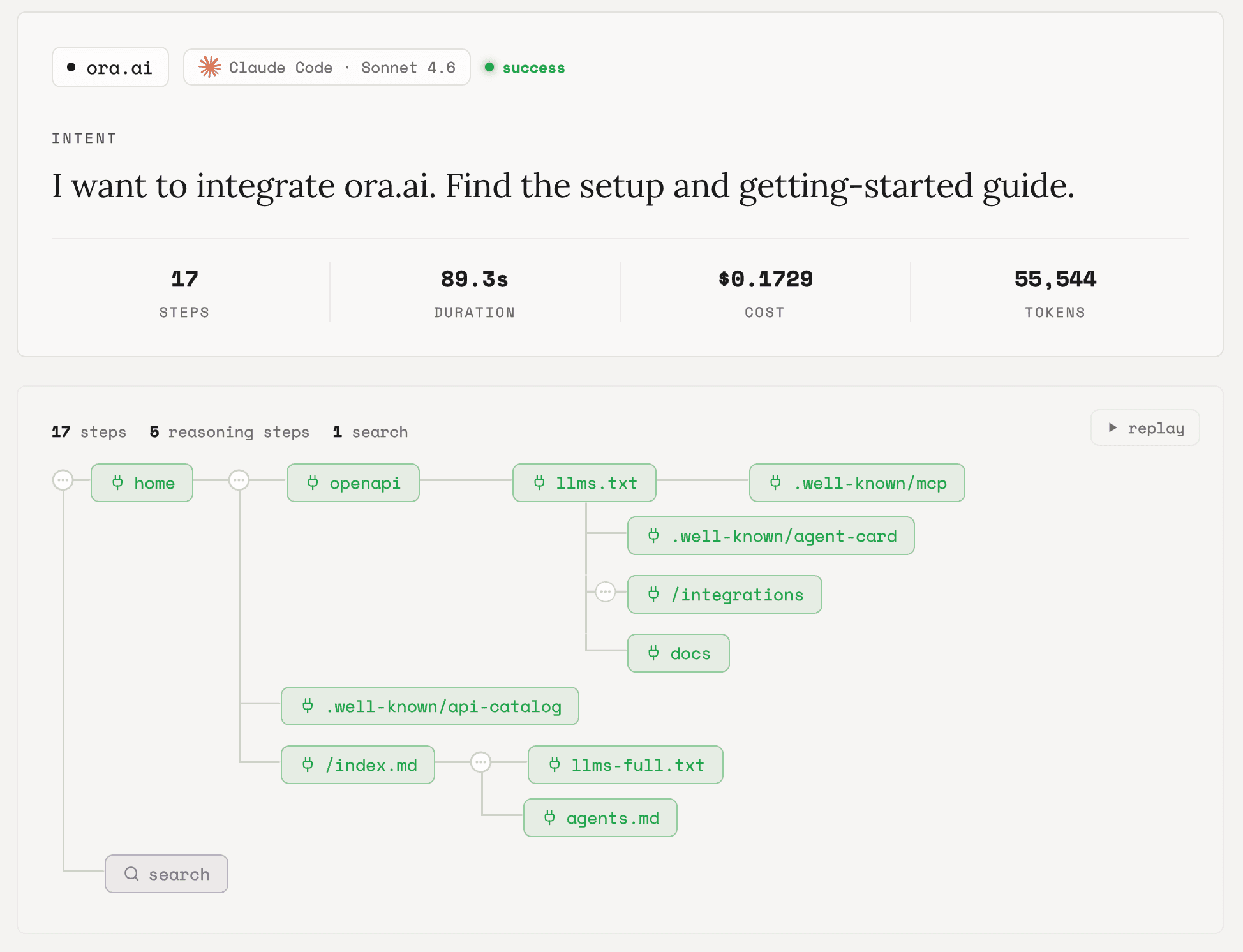
finding 01
Everything that isn’t docs falls off a cliff
How often each resource got used, once it existed on a site:
docs pages
homepage
llms.txt
.well-known/*
openapi.json
robots.txt / sitemap.xml
agents.md
llms-full.txt
Docs and homepages live in one tier. Everything we built specifically for machines lives in another, far below. The drop from documentation to the rest is a cliff.
finding 02
But agent-first formats win when they get a shot
On the one site in the set that shipped the full stack - and linked it properly - the numbers invert:
Same files. ~17% → ~72%. The difference is reachability.
Reachability is the difference.
finding 03
Agents search to find their way, not the answer
Most homepage and docs visits came from prior brand knowledge - the agent already knew where it was going.
Web search showed up in ~38% of runs. But when it did, it mostly handed the agent a URL, not a fact. The task still got completed from on-site content.
Search is the map. The site is the destination.

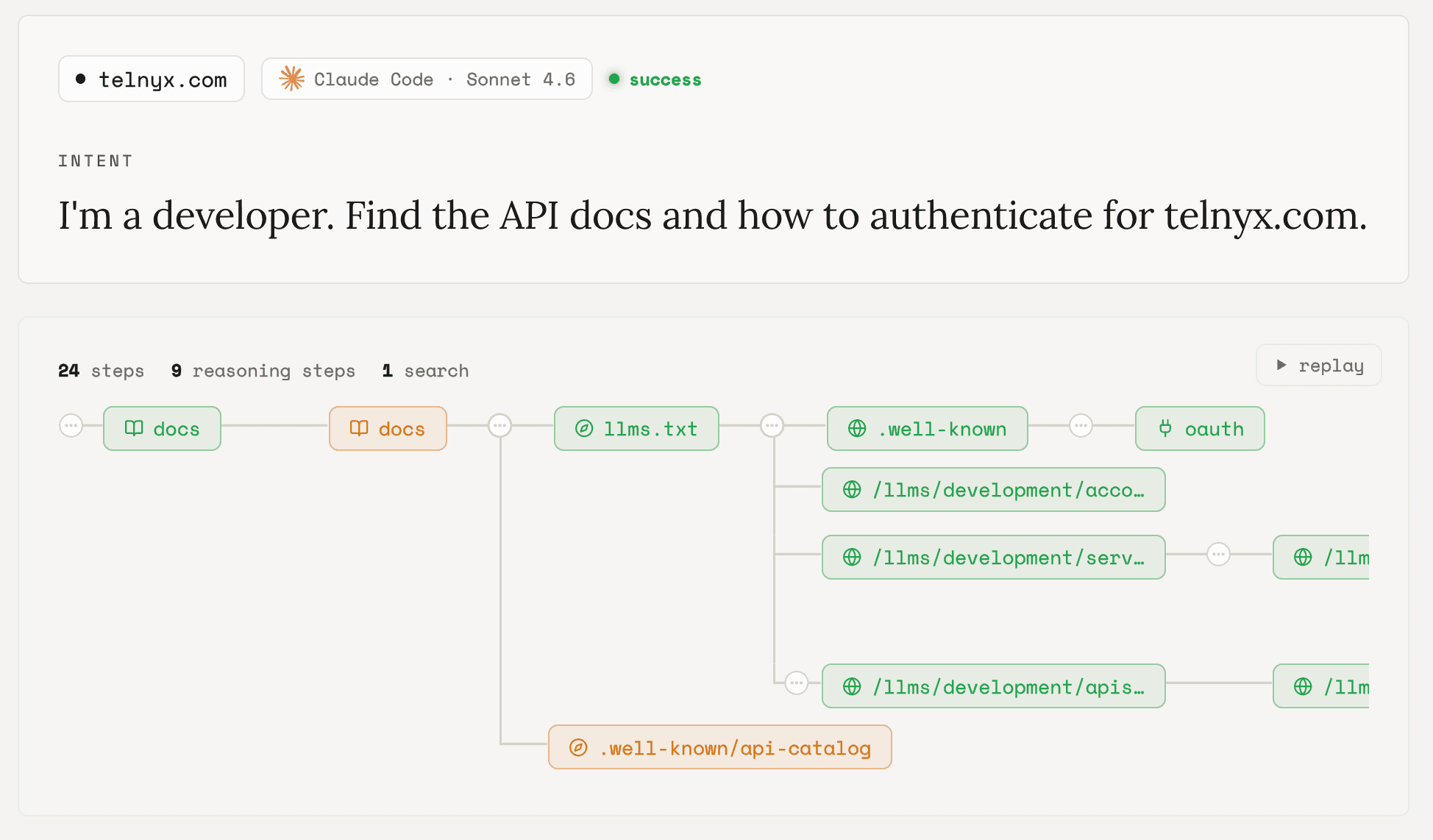
finding 04
AI-native files are reached late, and only by following links
Order of arrival, by turn:
A file nothing points to gets reached late, or never. An llms.txt no page references is a dead end.
finding 05
The homepage is the gateway, and the easiest place to break a run
Reached in ~84% of runs, almost always on turn one (~95%). It’s the front door for nearly every session.
Which makes it the most dangerous place to fail. Hide the navigation behind JavaScript and the agent goes blind from step one. Everything downstream depends on clearing this gate.
finding 06
Agents guess standard paths, so meet them where they look
Agents probe conventional URLs from habit. /pricing and /integrations get hit early, and they work when they exist.
But habit runs ahead of reality:
/api - guessed in ~11% of runs, found in ~2%.
Agents expect a convention most sites don’t serve. The fix is the cheapest one on this list: serve the paths agents already reach for.
.well-known/api-catalog on spec; when the convention is missing, that guess is a wasted reach.finding 07
Whatever an agent reaches, it uses, so wrong content is worse than none
Once a file is fetched, it shapes the answer almost every time. Agents build from the first believable page they land on. That cuts both ways:
+Good content gets used, readily.
!A reachable page with stale or wrong info hurts more than no page at all, because the agent will trust it and run.
Accuracy is load-bearing.
the one takeaway
Discovery is the bottleneck
Agents behave like well-informed visitors: they arrive at the front door from memory, fan out to docs, and follow links from there. The files we build for them are genuinely effective. They lose on discovery.
So the work is making the machine-readable formats reachable:
- Link to them from the pages agents already hit.
- Serve the conventional paths agents already guess -
/api,/pricing,/integrations. - Keep the homepage navigable without JavaScript.
- Treat every reachable page as gospel - because to an agent, it is.
Meet agents where they already look, and the formats built for them finally get their shot.